本篇文章将对网页结构进行讲解,若要进行深入学习,可在w3school看最权威的教程。本文还将重点玩一玩浏览器中的F12开发人员工具,开始手动实现爬虫中的“爬取”操作。
额,仍然没有开始写代码。如已了解本篇芝士,阔以直接跳至下一节教程。
HTML
HTML全称是超文本标记语言,它算不上是编程语言,但作为语言也有语法,写网页也就是在写HTML,下面是html网页的一般构造:
<html>
<head>
<meta ...>
<link ...>
<style></style>
<title></title>
</head>
<body>
...<div>...</div>...
<script></script>
</body>
</html>可以看到,html层次结构清晰分明,以<标签>开始,以</标签>结束,标签还可以添加属性,比如<div id='x1'>
<html>
<html>把所有的html代码包裹起来
<head>
<head>html头部,不显示网页内容,一般会引入一些CSS样式<style>`、给网页起**标题**`<title>
<body>
<body>顾名思义,“身体”,里面是html的内容,爬取资源一般也是在这个标签之下。
一般的网页在这个标签下都有很多个<div>`标签,还有`<script>
CSS
css是样式表,也是一种语言,可以给html里的一些元素预设样式,可以是以文件形式附加于html中,也可以直接将css代码放在html的style标签内部,以下是示例:
p {
text-align: center;
color: black;
font-family: arial;
}JS
JS全称是javascript,它是一种编程语言(图灵完备),可以响应鼠标键盘事件、操作html元素、以及进行各种高级操作,甚至有人用它写了C语言的编译器。和css类似,它也可以以文件形式附加于html中,也可以直接将其代码放在<script>`内(注意`<script>
var person = {
firstName: "Bill",
lastName : "Gates",
id : 678,
fullName : function() {
return this.firstName + " " + this.lastName;
}
};前端与后端
前端主要指的就是HTML、CSS、JS,在浏览网页时浏览器所下载的便是html、css、js代码,并将其渲染在浏览器内。
后端主要处理浏览器发来的请求,是服务器运行的程序,一般用Golang、Java、node.js、C++、Python等语言写成。
F12开发者工具
在浏览器里随便打开一个网页,按键盘上的F12键即可打开F12开发者工具窗口,chromium内核系的浏览器的开发者工具如下图所示:
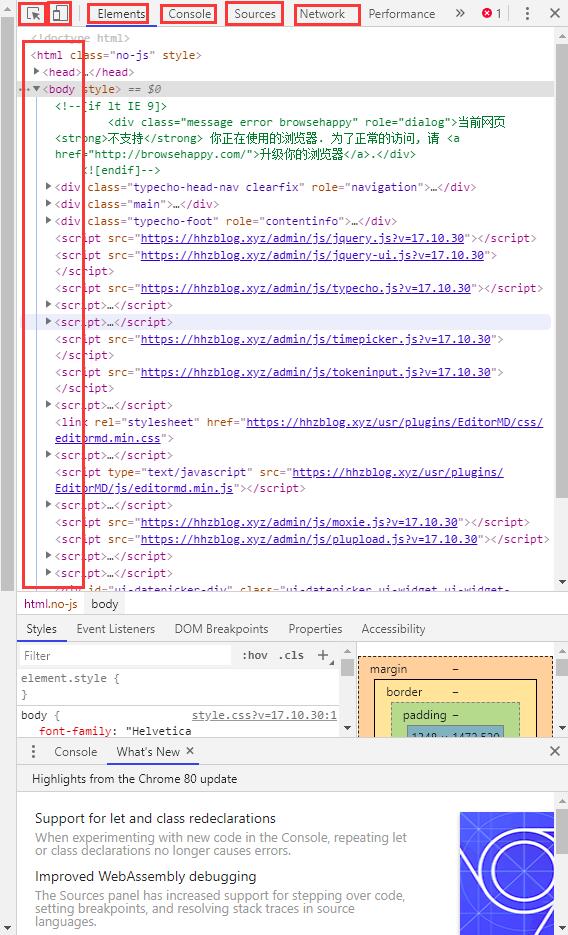
图中红框内标出的便是编写爬虫常用到的工具,其中
- 左上角按钮可定位页面中元素对应的html代码
- 右边一按钮可将网页以手机ua显示
- console中可使用js语言进行调试、操作页面元素,也可直接使用js语言在console中编写爬虫
- sources中可看到该网页所有的代码、图片等资源,也可在此页面中对js代码建立断点进行调试
- network中可对网站进行抓包